Run grammar check on posts
This commit is contained in:
parent
07f990ec1f
commit
8877a183e6
32 changed files with 144 additions and 144 deletions
|
|
@ -19,13 +19,13 @@ Email announcing the release
|
|||
|
||||
These updates, versions 3.0.1, 2.2.9, and 1.11.27, contain a fix for CVE-2019-19844, a vulnerability around the password reset mechanism, potentially enabling accounts to be hijacked, simply by knowing the user's email address. It was possible to receive the password reset email for an account you didn't control, reset their password, and hence gain access to the account. GitHub was hit by a very similar issue [only last month](https://eng.getwisdom.io/hacking-github-with-unicode-dotless-i/). Because of the high-profile nature of the vulnerability, and its high impact, the Django security team decided to release updates as quickly as possible, hence the small notification period.
|
||||
|
||||
It's around this time I realised today would be _interesting_.
|
||||
It's around this time I realized today would be _interesting_.
|
||||
|
||||
The vulnerability itself is a side-effect of how case-insensitive SQL queries work in many locale-aware database engines, and how this relates to email sending. The patches were applied to `django.contrib.auth.forms.PasswordResetForm`. Libraries which use this form directly, with little to no modification, such as `django-rest-auth`, shouldn't require any additional patches, besides bumping the Django version.
|
||||
The vulnerability itself is a side effect of how case-insensitive SQL queries work in many locale-aware database engines, and how this relates to email sending. The patches were applied to `django.contrib.auth.forms.PasswordResetForm`. Libraries which use this form directly, with little to no modification, such as `django-rest-auth`, shouldn't require any additional patches, besides bumping the Django version.
|
||||
|
||||
The exact fix for CVE-2019-19844 came in two parts: Fixing unicode comparison, and not trusting user input.
|
||||
|
||||
If your project, or a package you maintain, handles password reset in a custom way, however small, as `django-allauth` [did](https://github.com/pennersr/django-allauth/commit/9ec5a5456a59781771e1c3a0df3d555a0089accd), or overrides specific parts of `PasswordResetForm`, keep reading! Alternatively, if you're like me and find security vulnerabilities or weird unicode issues interesting, you should keep reading too.
|
||||
If your project or a package you maintain handles password reset in a bespoke way, however small, as `django-allauth` [did](https://github.com/pennersr/django-allauth/commit/9ec5a5456a59781771e1c3a0df3d555a0089accd), or overrides specific parts of `PasswordResetForm`, keep reading! Alternatively, if you're like me and find security vulnerabilities or weird unicode issues interesting, you should keep reading too.
|
||||
|
||||
## Unicode is hard
|
||||
|
||||
|
|
@ -33,7 +33,7 @@ If your project, or a package you maintain, handles password reset in a custom w
|
|||
What I'm about to talk about may be completely incorrect, because I, chances are much like you, find unicode a gloriously complicated, but rather interesting concept to grasp. I'm not sure anyone truly knows all its caveats, but if you know more than I do, and found something in the below which is wrong, please [tell me](https://twitter.com/RealOrangeOne).
|
||||
</disclaimer>
|
||||
|
||||
Contrary to what many people believe, computers can display a lot more than just letters and numbers. Or at least, what primarily english speakers consider letters and numbers - There are a lot more languages and character sets than just those used in the English language!
|
||||
Contrary to what many people believe, computers can display a lot more than just letters and numbers. Or at least, what primarily english speakers consider letters and numbers. There are a lot more languages and character sets than just those used in the English language!
|
||||
|
||||
Whilst I could go quite in depth about unicode, why it's great, why it's terrible, and why you really should be aware of it, [Tom Scott](https://www.tomscott.com/) has done a number of great videos on this, which I highly recommend checking out!
|
||||
|
||||
|
|
@ -78,22 +78,22 @@ Django's password reset request flow work like:
|
|||
|
||||
1. User sends their email address to Django
|
||||
2. Django validates what they sent looks like an email address
|
||||
3. Django fetches users who's email matches what's provided, _in a case-insensitive manner_
|
||||
3. Django fetches users whose email matches what's provided, _in a case-insensitive manner_
|
||||
4. Django filters out users who don't have usable passwords
|
||||
5. For each of those users, Django sends them an email containing a tokenized URL which can be used to reset their password
|
||||
5. For each of those users, Django emails them a tokenized URL which can be used to reset their password
|
||||
6. The user is informed "_If a user with this email exists_, we've sent them a password reset link"
|
||||
|
||||
Now, nothing in this flow is necessarily insecure, or necessarily secure. The proof is in the detail. In this case, the cause of the issue lies in step 5.
|
||||
|
||||
Once Django pulls users out of the database, and validates they have usable passwords, an email is crafted in memory for that users email. Importantly, said email address isn't the one from the database row, it's the one from the users request. But as we jsut learnt, a case-insensitive query can yield results which aren't exactly identical to the search term, meaning in malicious cases, they'll be different.
|
||||
Once Django pulls users out of the database, and validates they have usable passwords, an email is crafted in memory for that users email. Importantly, said email address isn't the one from the database row, it's the one from the users request. But as we just learnt, a case-insensitive query can yield results which aren't exactly identical to the search term, meaning in malicious cases, they'll be different.
|
||||
|
||||
Email addresses, and domain names for that matter, are widely accepted as being case insensitive. ME@GOOGLE.COM and me@google.com will probably end up in the same place, just as browsing to `GOOGLE.COM` will probably lead you to that ~~data collector~~ search engine you know and love.
|
||||
Email addresses, and domain names for that matter, are widely accepted as being case-insensitive. ME@GOOGLE.COM and me@google.com will probably end up in the same place, just as browsing to `GOOGLE.COM` will probably lead you to that ~~data collector~~ search engine you know and love.
|
||||
|
||||
The issue here lies in the fact that the two don't work in exactly the same way. PostgreSQL, and many other locale-aware storages consider the locale when comparing case-insensitive. DNS on the other hand, converts domains to [punycode](https://en.wikipedia.org/wiki/Punycode) before resolving, at which point the character becomes 'just another character'.
|
||||
|
||||
For example, the GitHub attack used the Turkish dotless i "ı". "GıtHub" isn't the same as "GitHub" to us, nor is it to DNS, where it becomes the punycode `gthub-2ub`, but as far as case-insensitive locale-correctness is concerned, they're the same, or at least the same enough.
|
||||
|
||||
Now this isn't a bash on PostgreSQL, what they're doing is definitely correct, and is required for the modern, multi-charset world. Nor am I bashing Python, or DNS, or anyting for that matter. Really, us humans are the issue, assuming that everything works in the nice super simple way we'd expect it to. We're wrong.
|
||||
Now this isn't a bash on PostgreSQL, what they're doing is definitely correct, and is required for the modern, multi-charset world. Nor am I bashing Python, or DNS, or anything for that matter. Really, us humans are the issue, assuming that everything works in the nice super simple way we'd expect it to. We're wrong.
|
||||
|
||||
## _"So how does all this relate to CVE-2019-19844?"_
|
||||
|
||||
|
|
@ -106,7 +106,7 @@ The exact patch can be seen [on GitHub](https://github.com/django/django/commit/
|
|||
|
||||
### Fixing unicode comparison
|
||||
|
||||
A modification was made to `PasswordResetForm.get_users`, to add an additional check. Once users were retrieved from the database, their email addresses were normalised, and compared against a normalised version of the user input, before being allowed through. This means even if the database returns a user which is like the provided email address, but different in a locale-aware manner, it will still be filtered out.
|
||||
A modification was made to `PasswordResetForm.get_users`, to add more validation. Once users were retrieved from the database, their email addresses were normalized, and compared against a normalized version of the user input, before being allowed through. This means even if the database returns a user which is like the provided email address, but different in a locale-aware manner, it will still be filtered out.
|
||||
|
||||
### User input sanitization
|
||||
|
||||
|
|
@ -114,7 +114,7 @@ Once users have been retrieved from the database using `PasswordResetForm.get_us
|
|||
|
||||
#### Non-obvious patch
|
||||
|
||||
The exact change to this isn't obvious. Take the below two code examples. These are two snippets of the same method on `PasswordResetForm`, taken from Django's `master` branch. one is vulnerable to CVE-2019-19844, the other is not.
|
||||
The exact change to this isn't obvious. Take the below two code examples. These are two snippets of the same method on `PasswordResetForm`, taken from Django's `master` branch. One is vulnerable to CVE-2019-19844, the other is not.
|
||||
|
||||
This method is vulnerable:
|
||||
|
||||
|
|
|
|||
|
|
@ -6,7 +6,7 @@ subtitle: Arch is well known for going wrong, but today was the first time this
|
|||
tags: [arch, linux]
|
||||
---
|
||||
|
||||
I'm one of those Arch users who _apparently_ doesn't use arch properly: I install updates daily, including packages from the AUR. This has the great benefit of giving me the most up-to-date packages available from upstream. However the downside of meaning I have the latest packages from upstream, meaning if something breaks, even temporarily, it breaks for me.
|
||||
I'm one of those Arch users who _apparently_ doesn't use arch properly: I install updates daily, including packages from the AUR. This has the great benefit of giving me the most up-to-date packages available from upstream. However, the downside of meaning I have the latest packages from upstream, meaning if something breaks, even temporarily, it breaks for me.
|
||||
|
||||
I'm also one of those _crazy_ people who uses arch on my work machine. Craziness aside, it's never caused me an issue, until today.
|
||||
|
||||
|
|
|
|||
|
|
@ -6,7 +6,7 @@ tags: [programming]
|
|||
|
||||
April marks the release of Django 2.2, the latest LTS version of the popular Python web framework. Django 2.2 marks almost two years of development since the last LTS release, 1.11 in April 2017, and brings with it some very large improvements and changes which naturally come with a major version bump.
|
||||
|
||||
Django historically works off the LTS pattern of software releasing, providing two channels. LTS versions are maintained far longer than regular versions, and receive regular bug fixes and security patches in line with the main release channel.
|
||||
Django historically works off the LTS pattern of software releasing, providing two channels. LTS releases are maintained far longer than regular versions, and receive regular bug fixes and security patches in line with the main release channel.
|
||||
|
||||
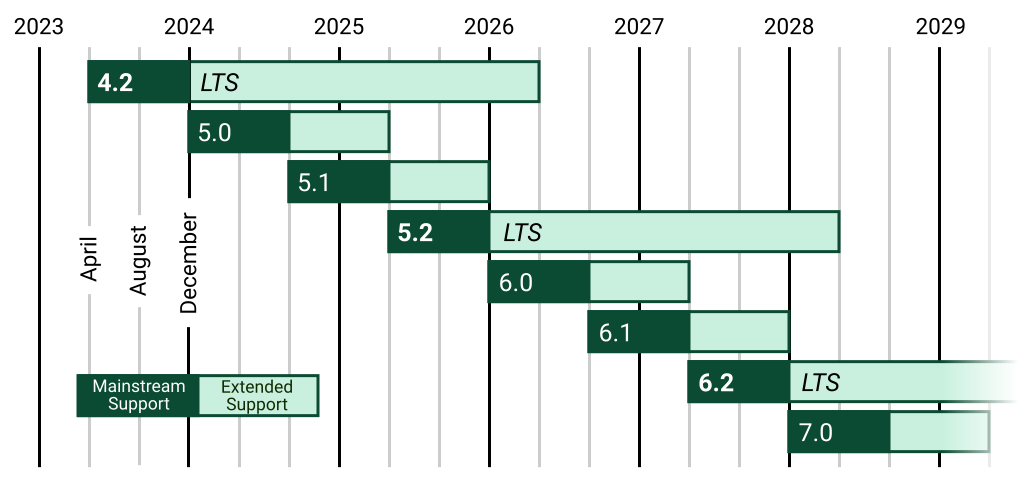
|
||||
|
||||
|
|
@ -128,7 +128,7 @@ With all these new functions, focusing around maths and string manipulation, dat
|
|||
|
||||
`QuerySet.iterator` is an efficient way of loading very large datasets into Django to be used. Simply iterating over a queryset loads the entire result set into memory, and then iterates over it as a `list`. `.iterator` uses cursors and pagination to chunk up the data, so a much smaller amount of data is stored in memory at once.
|
||||
|
||||
The new ability to specify a chunk size allows tuning of this to improve performance. The default is 2000, which represents something [close to how it worked before](https://www.postgresql.org/message-id/4D2F2C71.8080805%40dndg.it)
|
||||
The new ability to specify a chunk size allows tuning of this to improve performance. The default is 2000, which represents something [close to how it worked before](https://www.postgresql.org/message-id/4D2F2C71.8080805%40dndg.it).
|
||||
|
||||
### `QuerySet.values_list` can return named tuples
|
||||
|
||||
|
|
@ -154,7 +154,7 @@ Even though this exists, please don't use it in production!
|
|||
|
||||
## Secure JSON serialization into HTML
|
||||
|
||||
Anyone who's had to dump JSON blobs into HTML pages should have come across [`django-argonauts`](https://github.com/fusionbox/django-argonauts) (if you're doing this _without_ `django-argonauts`, fear). `django-argonauts` helps prevent multiple different classes of XSS attacks, which there's great examples of on the [project's README](https://github.com/fusionbox/django-argonauts#filter).
|
||||
Anyone who has dumped JSON blobs into HTML pages should have come across [`django-argonauts`](https://github.com/fusionbox/django-argonauts) (if you're doing this _without_ `django-argonauts`, fear). `django-argonauts` helps prevent multiple different classes of XSS attacks, which there are great examples of in the [project's README](https://github.com/fusionbox/django-argonauts#filter).
|
||||
|
||||
Django now has some built-in support for protecting against these kinds of attacks, from the new `json_script` filter. This takes an object in template context, serializes it to JSON (securely), and wraps it in a `script` tag, resulting in:
|
||||
|
||||
|
|
@ -201,9 +201,9 @@ Now, `request` objects have a `headers` attribute which allows a far more sane A
|
|||
|
||||
## Use of `sqlparse`
|
||||
|
||||
In previous versions, Django's ORM handled every aspect of constructing SQL queries. This added a lot of additional, and arguably unnecessary code to the core of Django. Django 2.2 adds a new dependency which takes care of this: `sqlparse`. `sqlparse` is a library to handle AST parsing of SQL, allowing the conversion from SQL text to Python objects, and vice versa. This doesn't extract Django's ORM into an external package, just remove a small section of it in favour of a existing library.
|
||||
In previous versions, Django's ORM handled every aspect of constructing SQL queries. This added a lot of additional, and arguably unnecessary code to the core of Django. Django 2.2 adds a new dependency which takes care of this: `sqlparse`. `sqlparse` is a library to handle AST parsing of SQL, allowing the conversion from SQL text to Python objects, and vice versa. This doesn't extract Django's ORM into an external package, just remove a small section of it in favour of an existing library.
|
||||
|
||||
Using an external library brings with it many benefits. There's now less code inside the core Django codebase, meaning there's less for the core developers to manage and tie in to Django's release cycle. **(Wild speculation alert!)** It also _might_ mean it gets faster. Society is built on specialisation, therefore hopefully a library designed to do SQL parsing will be faster and more robust than the one originally written for Django, and also takes some of the strain off the Django core team!
|
||||
Using an external library brings with it many benefits. There's now less code inside the core Django codebase, meaning there's less for the core developers to manage and tie in to Django's release cycle. **(Wild speculation alert!)** It also _might_ mean it gets faster. Society is built on specialization, therefore hopefully a library designed to do SQL parsing will be faster and more robust than the one originally written for Django, and also takes some strain off the Django core team!
|
||||
|
||||
## Watchman
|
||||
|
||||
|
|
@ -213,7 +213,7 @@ Watchman support isn't enabled by default. It requires an additional optional de
|
|||
|
||||
## Database instrumentation
|
||||
|
||||
Django supports many different ways of modifying the querying and model lifecycle, from executing arbitrary SQL, to using signals to listen for specific model events. Django 2.0 introduces instrumentation, which allows intermediary code to be executed for each query, enabling modification, logging, and any other munging of queries and data you need.
|
||||
Django supports many ways of modifying the querying and model lifecycle, from executing arbitrary SQL, to using signals to listen for specific model events. Django 2.0 introduces instrumentation, which allows intermediary code to be executed for each query, enabling modification, logging, and any other munging of queries and data you need.
|
||||
|
||||
An interesting use for this would be explicitly disabling queries in certain parts of the code, with [`django-zen-queries`](https://github.com/dabapps/django-zen-queries) (ships in https://github.com/dabapps/django-zen-queries/pull/12).
|
||||
|
||||
|
|
|
|||
|
|
@ -4,7 +4,7 @@ subtitle: "Duplicati + Rclone = :heart:"
|
|||
date: 2020-05-22
|
||||
---
|
||||
|
||||
[Duplicati](https://www.duplicati.com/) is one of my favourite backup system. It's pretty fast, supports a large number of backup sources, and has a nice configuration web UI. Unfortunately however, it can't be used to backup remote files. In fact, I can't find a nice fully-features backup solution which does do this, which sucks.
|
||||
[Duplicati](https://www.duplicati.com/) is one of my favourite backup system. It's pretty fast, supports numerous backup sources, and has a nice configuration web UI. Unfortunately however, it can't be used to back up remote files. In fact, I can't find a nice fully-features backup solution which does do this, which sucks.
|
||||
|
||||
Another great tool is [`rclone`](https://rclone.org/), which lets you list, download, upload and modify remote files. Because of this, you can use Rclone as a naive backup system, but it's not quite as powerful as Duplicati.
|
||||
|
||||
|
|
@ -20,7 +20,7 @@ My solution? Do just that! Have rclone mount the remotes I need, and point Dupli
|
|||
|
||||
## Setup
|
||||
|
||||
First, create a compose entry for `docker-rclone-mount`. Putting it in the same compose file as Duplicati makes life easier.
|
||||
First, create a docker compose entry for `docker-rclone-mount`. Putting it in the same compose file as Duplicati makes life easier.
|
||||
|
||||
```yml
|
||||
rclone:
|
||||
|
|
@ -54,7 +54,7 @@ Note the use of `:shared` on the end of both mounts. This is important as it all
|
|||
|
||||
Next step is to set up your rclone remote, which is best done through the rclone CLI. I recommend installing and configuring your remotes locally, and copying the config over, as it lest you ensure everything works correctly without having to jump around docker.
|
||||
|
||||
Final step is to tell `docker-rclone-mount` to mount your remote. This is done using the config file at `/config/config.txt`. The file contains an rclone remote, and a destination mount inside the container relative to `/mnt`, separated by a space.
|
||||
Final step is to tell `docker-rclone-mount` to mount your remote. This is done using the config file at `/config/config.txt`. The file contains a rclone remote, and a destination mount inside the container relative to `/mnt`, separated by a space.
|
||||
|
||||
```
|
||||
remote:data data
|
||||
|
|
|
|||
|
|
@ -8,7 +8,7 @@ In the current lockdown situation, a lot of people are starting to eye up that o
|
|||
|
||||
Naturally, once you've got something set up in your home, you might want to access it outside the house. Whether it be some bulk storage using [Nextcloud](https://nextcloud.com/), Feed aggregator using RSS, [HomeAssistant](https://www.home-assistant.io/) or even an IRC bouncer. I see questions about this pop up quite a lot, both on [r/selfhosted](https://www.reddit.com/r/selfhosted/) or the [SelfHosted](https://selfhosted.show/) podcast's [discord](https://discord.gg/n49fgkp) (go join by the way!).
|
||||
|
||||
One thing I see a lot is people recommending how they do it, or stating how someone should do it (I'm guilty of both!), but very few give multiple answers, and contrast between them. For someone getting started, it's almost as important to understand _why_ a given approach is important, as it is the approach itself.
|
||||
One thing I see a lot is people recommending how they do it, or stating how someone should do it (I'm guilty of both!), but very few people give multiple answers, and contrast between them. For someone getting started, it's almost as important to understand _why_ a given approach is important, as it is the approach itself.
|
||||
|
||||
## Techniques
|
||||
|
||||
|
|
@ -71,7 +71,7 @@ C-->E
|
|||
C-->F
|
||||
{{</mermaid>}}
|
||||
|
||||
The main caveat with this falls around dynamic IPs. Most residential IPs won't give your home a static IP. If you restart your router, or leave it long enough, you'll get a fresh IP. It might be the same, it might not. For this reason, it's not enough to simply set and forget your home's IP, because at some point, it'll change. For this reason you'll also need to run something which periodically updates your DNS records based on your home IP.
|
||||
The main caveat falls around dynamic IPs. Most residential IPs won't give your home a static IP. If you restart your router, or leave it long enough, you'll get a fresh IP. It might be the same, it might not. For this reason, it's not enough to simply set and forget your home's IP, because at some point, it'll change. For this reason you'll also need to run something which periodically updates your DNS records based on your home IP.
|
||||
|
||||
Another potential downside, however niche, is that public IPs of residential locations can be used to track down the location. If you're worried about that, or super paranoid, this might not be the solution for you! Because traffic flows direct, it also means that in the event of a spike of network traffic, your home internet connection may be impacted.
|
||||
|
||||
|
|
@ -109,7 +109,7 @@ E-->G
|
|||
E-->H
|
||||
{{</mermaid>}}
|
||||
|
||||
Because traffic flows between your device and the VPN server in your house over an encrypted VPN connection, it's incredibly secure regardless of what's going over it - even unencrypted HTTP traffic. This means that assuming your VPN is setup properly, it doesn't matter how the applications themselves are setup.
|
||||
Because traffic flows between your device and the VPN server in your house over an encrypted VPN connection, it's incredibly secure regardless of what's going over it - even unencrypted HTTP traffic. This means that assuming your VPN is configured properly, it doesn't matter how the applications themselves are set up.
|
||||
|
||||
VPN servers are incredibly lightweight, and will easily run on a Raspberry Pi. [PiVPN](https://www.pivpn.io/) in a great and simple way to get started. Contrary to its name, it can be installed on any Debian-based machine.
|
||||
|
||||
|
|
@ -160,7 +160,7 @@ If you're interested in setting up something like this, I've written articles fo
|
|||
|
||||
## Reverse Proxies
|
||||
|
||||
A key component of any of the above techniques is a reverse proxy. A reverse proxy is designed to handle all traffic coming to your server, and route it to the right application. Whether this be some PHP application, a docker container, or a completely different machine. The routing is done based on a path or domain, or both, which allows you to serve many many applications all from the same site.
|
||||
A key component of any of the above techniques is a reverse proxy. A reverse proxy is designed to handle all traffic coming to your server, and route it to the right application. Whether this be some PHP application, a docker container, or a completely different machine. The routing is done based on a path or domain, or both, which allows you to serve many applications all from the same site.
|
||||
|
||||
{{<mermaid caption="Reverse proxy routing traffic based on a domain, and mapping it to the correct service">}}
|
||||
graph LR
|
||||
|
|
@ -195,7 +195,7 @@ There are slightly different privacy and security characteristics of each of the
|
|||
|
||||
Having a homelab is great, as a learning opportunity, hobby, and a way to take back your privacy. Installing different pieces of software is very well documented, however no one really talks about how to expose them to the internet, properly.
|
||||
|
||||
There's many reasons to expose your lab to the internet. Access to your services outside the house, allowing other people access to your services, or hosting completely public services like a blog.
|
||||
There are many reasons to expose your lab to the internet. Access to your services outside the house, allowing other people access to your services, or hosting completely public services like a blog.
|
||||
|
||||
Personally, I run a VPN gateway on [Vultr](https://www.vultr.com/?ref=7167289), and it works really well for my needs. If I don't want a service exposed to the public, I can connect to the VPN tunnel myself and access applications through that.
|
||||
|
||||
|
|
|
|||
|
|
@ -5,7 +5,7 @@ date: 2019-01-18
|
|||
|
||||
# Cleaning up Facebook - Part 1
|
||||
|
||||
Around 10 years ago, Facebook was everything. No matter your interests, you could find like minded people on Facebook to share your passion with. But that communication came at a price: your personal data. In recent years, we've realised to what extend Facebook was selling our data and generally invading our privacy. After the [Cambridge Analytics scandal](https://www.nytimes.com/2018/04/04/us/politics/cambridge-analytica-scandal-fallout.html) from March 2018 showed the extent Facebook was collecting our data, and mistreating it for financial gain.
|
||||
Around 10 years ago, Facebook was everything. No matter your interests, you could find like-minded people on Facebook to share your passion with. But that communication came at a price: your personal data. In recent years, we've realized to what extent Facebook was selling our data and generally invading our privacy. After the [Cambridge Analytics scandal](https://www.nytimes.com/2018/04/04/us/politics/cambridge-analytica-scandal-fallout.html) from March 2018 showed the extent Facebook was collecting our data, and mistreating it for financial gain.
|
||||
|
||||
In my youth, I was a terrible Facebook user, posting random thoughts which came into my head, sharing loads of personal information and sharing weird memes (or what passed for memes in 2010, anyway). In recent years, as my passion for security and privacy thrived, I've attempted to undo the damage my younger self did.
|
||||
|
||||
|
|
@ -13,9 +13,9 @@ It's now 2019, and my plan for this new year is to slowly go through my Facebook
|
|||
|
||||
## Techniques
|
||||
|
||||
### Cleaning up posts - Facebook memories
|
||||
### Cleaning up posts: Facebook memories
|
||||
|
||||
[Facebook memories](https://www.facebook.com/help/439014052921484/) shows you things you did on Facebook on this day day in previous years. Using this, you can go through things posted to your Facebook, and delete them, slowly but surely. Spending a minute or so a day over the course of a year to clean up Facebook really works! I've been doing this for just over two weeks, and I've already deleted 22 posts!
|
||||
[Facebook memories](https://www.facebook.com/help/439014052921484/) shows you things you did today on Facebook in previous years. Using this, you can go through things posted to your Facebook, and delete them, slowly but surely. Spending a minute or so a day over the course of a year to clean up Facebook really works! I've been doing this for just over two weeks, and I've already deleted 22 posts!
|
||||
|
||||
### Unliking pages
|
||||
|
||||
|
|
|
|||
|
|
@ -3,7 +3,7 @@ title: Privacy-respecting analytics with GoAccess
|
|||
date: 2020-04-10
|
||||
---
|
||||
|
||||
Recently, I decided to try and put some analytics on my website. Would be nice to see what view number are like and what pages get the most traffic.
|
||||
Recently, I decided to put some analytics on my website. Would be nice to see what view number are like and what pages get the most traffic.
|
||||
|
||||
Most people would just stick [Google Analytics](https://analytics.google.com/) on and be done with. But the privacy implications off that are huge and terrible, not to mention any self-respecting privacy extension would block it almost immediately.
|
||||
|
||||
|
|
@ -15,7 +15,7 @@ A quick internet search shows a plethora of alternatives which respect privacy,
|
|||
|
||||
## Enter GoAccess
|
||||
|
||||
[GoAccess](https://goaccess.io/) is an amazing tool to find and analyse log files, and build a report. The report is just simple boring analytics, nothing complex, plain and simple! The reports can either be in the form of a terminal ncurses-line interface, or a HTML report. This HTML report is a single file, so there's no complex server required. The HTML report also supports live update through websockets.
|
||||
[GoAccess](https://goaccess.io/) is an amazing tool to find and analyse log files, and build a report. The report is just simple boring analytics, nothing complex, plain and simple! The reports can either be in the form of a terminal ncurses-line interface, or an HTML report. This HTML report is a single file, so there's no complex server required. The HTML report also supports live update through websockets.
|
||||
|
||||
Unfortunately, this websocket functionality requires GoAccess to be exposed on a fixed port relative to the report, which wasn't ideal to my use case. It'd be yet another service to expose, ports to map, firewall rules to open, far too much hassle.
|
||||
|
||||
|
|
|
|||
|
|
@ -9,7 +9,7 @@ Hacktoberfest is a great initiative created by DigitalOcean and GitHub to get mo
|
|||
|
||||
Last year, I also entered, but due to some delivery issues, I never got the T-Shirt ([I'm still annoyed!](https://twitter.com/RealOrangeOne/status/949781289254703106)). So this year I'm making sure I get it!
|
||||
|
||||
As someone who does a lot of development on GitHub, the messages behind hacktoberfest are somewhat lost on me. I already open lots of pull requests against projects, and know how to do them properly, but I know others don't. By the looks of the global statistics, I can safely see it works! I still try and recommend to every dev to sign up to hacktoberfest, even if they don't proactively look for issues. If it raises awareness for open source projects, gets more people into helping the community, and results in better software, then what's there to lose!
|
||||
As someone who does a lot of development on GitHub, the messages behind hacktoberfest are somewhat lost on me. I already open lots of pull requests against projects, and know how to do them properly, but I know others don't. By the looks of the global statistics, I can safely see it works! I still recommend every dev sign up to hacktoberfest, even if they don't proactively look for issues. If it raises awareness for open source projects, gets more people into helping the community, and results in better software, then what's there to lose!
|
||||
|
||||
## My Contributions
|
||||
|
||||
|
|
|
|||
|
|
@ -13,7 +13,7 @@ In [2018]({{< relref "hacktoberfest-2018" >}}), I submitted a total of 10 pull r
|
|||
|
||||
## My contributions
|
||||
|
||||
Whilst DigitalOcean did have an official checker this year, it was garbage! Not only was it incredibly slow, but it was only possible to see _your_ pull requests, rather than any user. Instead, the third-party [Hacktoberfest Checker](https://hacktoberfestchecker.jenko.me/user/RealOrangeOne) shows the relevant pull requests.
|
||||
Whilst DigitalOcean did have an official checker this year, it was pretty bad! Not only was it incredibly slow, but it was only possible to see _your_ pull requests, rather than any user. Instead, the third-party [Hacktoberfest Checker](https://hacktoberfestchecker.jenko.me/user/RealOrangeOne) shows the relevant pull requests.
|
||||
|
||||
### 3 Contributions to `srobo/team-emails`
|
||||
|
||||
|
|
@ -68,4 +68,4 @@ Whilst DigitalOcean did have an official checker this year, it was garbage! Not
|
|||
|
||||
## Overview
|
||||
|
||||
As with last year, I personally consider many of these contributions invalid, primarily because they don't really fit with the spirit of Hacktoberfest. Namely, all those under the `srobo` organisation don't especially fit, and the ones on my own repos. Excluding those, there's still more than enough to get my t-shirt!
|
||||
As with last year, I personally consider many of these contributions invalid, primarily because they don't really fit with the spirit of Hacktoberfest. Namely, all those under the `srobo` organization don't especially fit, and the ones on my own repos. Excluding those, there's still more than enough to get my t-shirt!
|
||||
|
|
|
|||
|
|
@ -43,11 +43,11 @@ The method suggested in the [implementation PR](https://github.com/keepassxreboo
|
|||
|
||||
dd if=/dev/urandom of=keyfile.key bs=2048 count=1
|
||||
|
||||
This generates a 2048-bit key file using the system's random number generator. This is perfectly secure enough to generate random numbers, but, I like to use something even more secure:
|
||||
This generates a 2048-bit key file using the system's random number generator which is perfectly secure enough to generate random numbers, but, I like to use something even more secure:
|
||||
|
||||
head -c 65535 /dev/zero | openssl enc -aes-256-ctr -pass pass:"$(dd if=/dev/urandom bs=128 count=1 2>/dev/null | base64)" -nosalt > keyfile.key
|
||||
|
||||
[This](https://serverfault.com/a/714412) uses a mixture of OpenSSL, and the system's random number generator. I don't exactly know what the command is doing, but it looks more complex, so that must mean it's more cryptographically secure, right?
|
||||
[The above](https://serverfault.com/a/714412) uses a mixture of OpenSSL, and the system's random number generator. I don't exactly know what the command is doing, but it looks more complex, so that must mean it's more cryptographically secure, right?
|
||||
|
||||
### Install the new key
|
||||
To use the new key, you need to change the key file in the master key settings (Database > Change master key). Select the new key, and enter your current password, and apply. As this re-encrypts the database with a new master key, you can enter a new password here to change it.
|
||||
|
|
|
|||
|
|
@ -41,7 +41,7 @@ Alternative extensions are available, although many of the more powerful ones co
|
|||
|
||||
On most _sane_ Operating Systems, Home/end operate differently depending on focus. When in a textbox, they control the cursor on the line, and the window everywhere else. On macOS, it seems to be different. Home / End always controls the page, whilst `CMD` + arrows control the cursor. I mostly had this issue with Firefox.
|
||||
|
||||
A part of me likes the fact it's explicit and different, but the muscle memory is too much to get over! It's also very rare
|
||||
A part of me likes the fact it's explicit and different, but the muscle memory is too much to get over! It's also very rare.
|
||||
|
||||
### Screen brightness varies
|
||||
|
||||
|
|
@ -57,7 +57,7 @@ Historically, package installation on macOS has been in the form of `.dmg` files
|
|||
|
||||
`brew` is the command-line package manager for macOS, allowing simple installation of almost any application and service for macOS. `brew cask` is an extension for this, designed specifically for GUI applications. It also means each application has to update in its own special way.
|
||||
|
||||
As someone who's used to the AUR, this felt great! one command to install and update almost any application I need.
|
||||
As someone who's used to the AUR, this felt great! One command to install and update almost any application I need.
|
||||
|
||||
#### Global emoji-picker is awesome!
|
||||
|
||||
|
|
@ -81,7 +81,7 @@ No matter how many times I removed them, some applications kept returning to the
|
|||
|
||||
Anyone who's used macOS will know that its support for screenshots was clearly not designed for users in mind. Standard keyboards have an incredibly useful 'Print Screen' key, which captures the screen, and is aptly named. macOS has the _equally obvious_ `CMD + Shift + 4`.
|
||||
|
||||
Apple maintain a comprehensive, but unnecessarily complex [support page](https://support.apple.com/en-us/HT201361) on how to take screenshots. There are many 3rd-party applications available to make this process easier, my personal favourites being [Skitch](https://evernote.com/products/skitch) and [Lightshot](https://app.prntscr.com/en/index.html).
|
||||
Apple maintains a comprehensive, but unnecessarily complex [support page](https://support.apple.com/en-us/HT201361) on how to take screenshots. There are many 3rd-party applications available to make this process easier, my personal favourites being [Skitch](https://evernote.com/products/skitch) and [Lightshot](https://app.prntscr.com/en/index.html).
|
||||
|
||||
### Scroll-wheel acceleration
|
||||
|
||||
|
|
|
|||
|
|
@ -13,11 +13,11 @@ KeePassXC, before it looked pretty
|
|||
|
||||
Fortunately, there's a solution, and it comes in the form of a _Theme engine_. Theme engines act as a small compatibility layer, allowing certain frameworks to render as if they were others. With this, we can tell QT applications to render as if they were GTK.
|
||||
|
||||
`qt5-styleplugins` is a package which allows QT applications it's components using the same underlying widget components as GTK+2. More detail on `qt5-styleplugins` can be found on the [Arch Wiki](https://wiki.archlinux.org/index.php/Uniform_look_for_Qt_and_GTK_applications#QGtkStyle)
|
||||
`qt5-styleplugins` is a package which allows QT applications it's components using the same underlying widget components as GTK+2. More detail on `qt5-styleplugins` can be found on the [Arch Wiki](https://wiki.archlinux.org/index.php/Uniform_look_for_Qt_and_GTK_applications#QGtkStyle).
|
||||
|
||||
Setting up `qt5-styleplugins` is incredibly simple:
|
||||
|
||||
1. Install the package from your OS's package manager. ([`qt5-styleplugins`](https://www.archlinux.org/packages/?name=qt5-styleplugins) on Arch, [`qt5-style-plugins`](https://packages.ubuntu.com/search?keywords=qt5-style-plugins) on Ubuntu)
|
||||
1. Install the package from your OS's package manager. [`qt5-styleplugins`](https://www.archlinux.org/packages/?name=qt5-styleplugins) on Arch, [`qt5-style-plugins`](https://packages.ubuntu.com/search?keywords=qt5-style-plugins) on Ubuntu.
|
||||
2. Set the environment variable: `QT_QPA_PLATFORMTHEME=gtk2`
|
||||
|
||||
Installing the environment variable can't be done in your `.bashrc`, as variables stored here aren't accessible to applications launched outside the terminal. I'd recommend setting it in `/etc/environment` instead.
|
||||
|
|
|
|||
|
|
@ -10,7 +10,7 @@ Speaking to those who have installed arch before, they say _"oh, it's simple"_ a
|
|||
|
||||
## Gotchas
|
||||
|
||||
So here's my one stop shop of the things which caught me up during the install and setup process. Whilst I did this install on my [XPS 15], it's all pretty generic.
|
||||
So here's my one stop shop of the things which caught me up during the install and set up process. Whilst I did this install on my XPS 15, it's all pretty generic.
|
||||
|
||||
### Use a wired network
|
||||
|
||||
|
|
@ -39,7 +39,7 @@ Fortunately, if you *do* forget to set a password, you can just reboot into the
|
|||
|
||||
### `base-devel`
|
||||
|
||||
Most of the guides I saw for installing arch simply said to install the `base` package group. Originally I took this advise, thinking `base-devel` contained things I didn't need to do kernel-level development on the OS. I was wrong.
|
||||
Most of the guides I saw for installing arch simply said to install the `base` package group. Originally I took this advice, thinking `base-devel` contained things I didn't need to do kernel-level development on the OS. I was wrong.
|
||||
|
||||
Whilst `base-devel` does contain many developer-related packages, such as `gcc` and `make`, it also contains some important system utilities, namely `sudo`, `file`, `which` and `grep`. You can see the full list of packages [here](https://www.archlinux.org/groups/x86_64/base-devel/), but changes are you want most of these, so just install it.
|
||||
|
||||
|
|
|
|||
|
|
@ -5,7 +5,7 @@ image: resource:editing-my-stack.png
|
|||
hide_header_image: true
|
||||
---
|
||||
|
||||
As a software engineer and perfectionist, I have my machines setup in a very specific way, so I can do my job properly and have everything just the way I like it. Thanks to my [dotfiles]({{< relref "projects/dotfiles" >}}), I have everything syncing up between machines, meaning the tools I use are setup correctly, the same, everywhere.
|
||||
As a software engineer and perfectionist, I have my machines set up in a very specific way, so I can do my job properly and have everything just the way I like it. Thanks to my [dotfiles]({{< relref "projects/dotfiles" >}}), I have everything syncing up between machines, meaning the tools I use are configured correctly, the same, everywhere.
|
||||
|
||||
# OS
|
||||
My current distro of choice is [Arch](https://www.archlinux.org/), specifically [Antergos](https://antergos.com/). My main reason for choosing arch is the [AUR](https://aur.archlinux.org/). Almost every package I can think of is packaged there, often by the community. It's great to be able to install things through one method and have everything update in a single command. Antergos is also far easier to install than raw arch, and has little to no bloat that comes with it.
|
||||
|
|
@ -28,7 +28,7 @@ My primary editor is [IntelliJ](https://www.jetbrains.com/idea/). [PyCharm](http
|
|||
If I'm just editing a file quickly, whether it be config from the terminal, or a quick script, I really like [Vim](http://www.vim.org/) for this. It's insanely fast and lightweight. I have a [custom `vimrc`](https://github.com/amix/vimrc) installed to change it to support more features than stock.
|
||||
|
||||
# Shell
|
||||
Whilst I use [ZSH](https://www.zsh.org/), I'm not a fan of the [super fancy themes](https://github.com/robbyrussell/oh-my-zsh/wiki/External-themes) for it, which display your current git branch, node version, time, all that jazz. My terminal is a take on the default colourised Debian terminal, with a lambda symbol who's colour changes depending on the return code of the previous command.
|
||||
Whilst I use [ZSH](https://www.zsh.org/), I'm not a fan of the [super fancy themes](https://github.com/robbyrussell/oh-my-zsh/wiki/External-themes) for it, which display your current git branch, node version, time, all that jazz. My terminal is a take on the default colourized Debian terminal, with a lambda symbol who's colour changes depending on the return code of the previous command.
|
||||
|
||||
{{< resource src="shell-prompt.png" >}}
|
||||
My shell prompt
|
||||
|
|
@ -43,7 +43,7 @@ I do have a fair number of plugins and aliases, thanks to both [oh my ZSH](http:
|
|||
I've been a [Firefox](https://www.mozilla.org/en-GB/firefox/) user for as long as I can remember, and I've got no reason to stop now. In the recent [Quantum](https://blog.mozilla.org/blog/2017/11/14/introducing-firefox-quantum/) update, it's only got faster! I've seen some very promising things from [Vivaldi](https://vivaldi.com/), but it's missing some key features, and is a little too buggy for me to use full-time.
|
||||
|
||||
## For development
|
||||
I currently switch between [Firefox](#browser) and [Chromium](https://www.chromium.org/) right now for development. Currently chromium's dev tools are quite a bit nicer than Firefox's, and I've had issues with some projects causing Firefox to spike my CPU and cause my system to crash.
|
||||
I currently switch between [Firefox](#browser) and [Chromium](https://www.chromium.org/) right now for development. Chromium's dev tools are quite a bit nicer than Firefox's, and I've had issues with some projects causing Firefox to spike my CPU and cause my system to crash.
|
||||
|
||||
# Password manager
|
||||
I've switched around password managers _a lot_, but I'm currently settled on [KeePassXC](https://keepassxc.org/), a community fork of [KeePassX](https://www.keepassx.org/), which is a cross-platform fork of [KeePass](https://keepass.info/). When it comes to cross-platform password managers, there's very little out there that's also open-source. I can access password on both my linux machines, and [my phone](https://github.com/PhilippC/keepass2android), and my windows OS when I occasionally have to use it. The [browser integration](https://addons.mozilla.org/en-US/firefox/addon/keepasshttp-connector/) is also pretty nice too!
|
||||
|
|
|
|||
|
|
@ -13,7 +13,7 @@ I'm still an [Antergos](https://antergos.com/) user, and have no sign of changin
|
|||
|
||||
## Desktop
|
||||
|
||||
As with last year, I'm still loving [i3](https://i3wm.org/), I can't live without a tiled window manager now. For stability, and because I don't like random unicode characters on my bar, I've switched from [`i3status-rs`](https://github.com/greshake/i3status-rust) and [`i3status`](https://github.com/i3/i3status) to [polybar](https://polybar.github.io/), which looks so much nicer!
|
||||
As with last year, I'm using [i3](https://i3wm.org/), and loving it! I can't live without a tiled window manager now. For stability, and because I don't like random unicode characters on my bar, I've switched from [`i3status-rs`](https://github.com/greshake/i3status-rust) and [`i3status`](https://github.com/i3/i3status) to [polybar](https://polybar.github.io/), which looks so much nicer!
|
||||
|
||||
My favourite addition of the year is [Flameshot](https://github.com/lupoDharkael/flameshot), a screenshot tool which allows selection, basic editing, and uploading.
|
||||
|
||||
|
|
@ -26,7 +26,7 @@ Flameshot in action
|
|||
My primarily editor is now [VSCode](https://code.visualstudio.com/), because it's faster and lighter-weight than IntelliJ. All the features I need from a large editor, but doesn't take 10 minutes to load! Because VSCode stores its configuration in plain files, in a very simple way, it's easy to sync it between machines, [which I do](https://github.com/RealOrangeOne/dotfiles/blob/master/tasks/vscode.yml).
|
||||
|
||||
## Markdown
|
||||
Last year, I was a fan of [Caret](https://caret.io/), and was eagerly awaiting version 4, which was in beta last year. one year on, and still no closer to seeing anything. It's for that reason I've switched back to [GhostWriter](https://github.com/wereturtle/ghostwriter/). Also because free and open source is great!
|
||||
Last year, I was a fan of [Caret](https://caret.io/), and was eagerly awaiting version 4, which was in beta last year. One year on, and still no closer to seeing anything. It's for that reason I've switched back to [GhostWriter](https://github.com/wereturtle/ghostwriter/). It's also free and open source, which is great!
|
||||
|
||||
## Quick files edits
|
||||
Nothing beats [Vim](http://www.vim.org/) for anything like this. I've switched my default editor for git commit messages, and have it installed on all my servers. I'm still unfamiliar with many of the advanced keyboard shortcuts, but I can navigate around a file just well enough for me.
|
||||
|
|
@ -58,7 +58,7 @@ The desktop client for Mullvad whilst functional, isn't great. I recently found
|
|||
|
||||
# Email
|
||||
|
||||
After realising that the benefits of [Mailfence](https://mailfence.com/) weren't useful to me, as there's no way I'm uploading a private key, I switched. [FastMail](https://www.fastmail.com/) has all the features I could ever need, and a great UI.
|
||||
After realizing that the benefits of [Mailfence](https://mailfence.com/) weren't useful to me, as there's no way I'm uploading a private key, I switched. [FastMail](https://www.fastmail.com/) has all the features I could ever need, and a great UI.
|
||||
|
||||
## Email Client
|
||||
My email client has stayed the same. There really is nothing close to [Thunderbird](https://www.thunderbird.net/en-GB/) on Linux! Mailspring does look nice, but it's still not quite feature-complete for my needs. And the fact Thunderbird is also a calendar app is quite useful too!
|
||||
|
|
@ -68,7 +68,7 @@ It might seem outdated, but I still quite like RSS. For me, it acts as a nice wa
|
|||
|
||||
# Mobile Podcast Player
|
||||
|
||||
In the last year, I've got majorly into podcasts. It's making my drive to work so much more interesting! [Castbox](https://castbox.fm/) was my player of choice in the past, but in the last few months I shelled out for [Pocket Casts](https://www.pocketcasts.com/). It's a more polished experience, and it doesn't screw with the bluetooth connection in my car quite as much!
|
||||
In the last year, I've got massively into podcasts. It's making my drive to work so much more interesting! [Castbox](https://castbox.fm/) was my player of choice in the past, but in the last few months I shelled out for [Pocket Casts](https://www.pocketcasts.com/). It's a more polished experience, and it doesn't screw with the bluetooth connection in my car quite as much!
|
||||
|
||||
# Dotfiles
|
||||
|
||||
|
|
|
|||
|
|
@ -9,7 +9,7 @@ Personally, I quite liked the old interface: A simple plaintext editor with synt
|
|||
|
||||
However, I do quite a lot through the nextcloud web UI, including write this post, so an interface I enjoy is quite important.
|
||||
|
||||
Another unfortunate side-effect of the new WYSIWYG text editor, is the lack of ability to edit plaintext files, such as code snippets, through the UI.
|
||||
Another unfortunate side effect of the new WYSIWYG text editor, is the lack of ability to edit plaintext files, such as code snippets, through the UI.
|
||||
|
||||
## Restoring the previous UI
|
||||
|
||||
|
|
@ -17,14 +17,14 @@ Fortunately, it's possible to restore the old UI in all its glory, with the inst
|
|||
|
||||
### [`files_texteditor`](https://github.com/nextcloud/files_texteditor/)
|
||||
|
||||
`files_texteditor` is an offical app which adds a simple but fammiliar plaintext editor to nextcloud, restoring the functionality of the original app from Nextcloud <16.
|
||||
`files_texteditor` is an official app which adds a simple but familiar plaintext editor to nextcloud, restoring the functionality of the original app from Nextcloud <16.
|
||||
|
||||
### [`files_markdown`](https://github.com/icewind1991/files_markdown)
|
||||
|
||||
`files_markdown` is the extension most people will be wanting. This is an extension which brings back the previous markdown editor, and makes it the default editor for markdown files, restoring Nextcloud's markdown editing experience to its former glory.
|
||||
`files_markdown` is the extension most people will be after. This is an extension which brings back the previous markdown editor, and makes it the default editor for markdown files, restoring Nextcloud's markdown editing experience to its former glory.
|
||||
|
||||
## Profit?
|
||||
|
||||
With these installed, Nextcloud finally works the way I need it to.
|
||||
|
||||
I didn't discover this myself, but I did spent far too long looking into it. The exact instructions were from a [GitHub issue](https://github.com/icewind1991/files_markdown/issues/136#issuecomment-560134316).
|
||||
I didn't discover this myself, but I did spend far too long looking into it. The exact instructions were from a [GitHub issue](https://github.com/icewind1991/files_markdown/issues/136#issuecomment-560134316).
|
||||
|
|
|
|||
|
|
@ -5,7 +5,7 @@ date: 2020-03-05
|
|||
tags: [linux,security]
|
||||
---
|
||||
|
||||
When disabling a user account on a Linux box, it's good practice to also change the shell to something which, well, isn't a shell. The point of these shells is rather than presenting the user with a prompt to execute further commands , it returns a failure code, and log out the user.
|
||||
When disabling a user account on a Linux box, it is good practice to also change the shell to something which, well, isn't a shell. The point of these shells is rather than presenting the user with a prompt to execute further commands, it returns a failure code, and log out the user.
|
||||
|
||||
If you look around, people recommend a couple different things to set as the user's shell: `/bin/nologin` and `/bin/false`. Not once have I seen someone say why to use either, nor what the differences are.
|
||||
|
||||
|
|
@ -19,15 +19,15 @@ The source code itself is slightly misleading. `false` is actually an extension
|
|||
|
||||
The real logic actually lives there: [`true.c`](https://git.savannah.gnu.org/cgit/coreutils.git/tree/src/true.c)
|
||||
|
||||
Both `true` and `false` are incredibly simple, even if you nothing about C. And as a result are incredibly fast.
|
||||
Both `true` and `false` are incredibly simple, even if you know nothing about C. And as a result are incredibly fast.
|
||||
|
||||
## `/bin/nologin`
|
||||
|
||||
`nologin` is designed to do exactly what we want it to. It's specifically designedo to prevent login by being set as a user's shell.
|
||||
`nologin` is designed to do exactly what we want it to. It's specifically designed to prevent login by being set as a user's shell.
|
||||
|
||||
`nologin` does a little more than false, but it's still very simple code to read: [`nologin.c`](https://git.kernel.org/pub/scm/utils/util-linux/util-linux.git/tree/login-utils/nologin.c)
|
||||
|
||||
Once executed, `nologin` will try and read `/etc/nologin.txt` to get a custom message to show the user. If it exists, it prints that and exits with code 1. If it doesn't exist, it shows the default message, and exits with code 1. This customization makes it much more user friendly, although because the file is global, one system can only have one configured message.
|
||||
Once executed, `nologin` will try to read `/etc/nologin.txt` to get a custom message to show the user. If it exists, it prints that and exits with code 1. If it doesn't exist, it shows the default message, and exits with code 1. This customization makes it much more user-friendly, although because the file is global, one system can only have one configured message.
|
||||
|
||||
## `rssh`
|
||||
|
||||
|
|
@ -39,6 +39,6 @@ Once executed, `nologin` will try and read `/etc/nologin.txt` to get a custom me
|
|||
|
||||
Realistically, it doesn't really matter. The point of a disabled prompt is to exit with a fail quickly, which both `false` and `nologin` do. So long as you block access, it really doesn't matter how.
|
||||
|
||||
If you're hyper paranoid, use `false`, as it's simpler and smaller. But you'll want to pair that with a whole lot more lockdown if you want things that locked down. Alternatively, if you want it to be more obvivous what's going on, use `nologin`, as its name makes a bit more sense, and terminates with a message.
|
||||
If you're hyper paranoid, use `false`, as it's simpler and smaller. But you'll lot more than just use `false` if you want things that locked down. Alternatively, if you want it to be more obvious what's going on, use `nologin`, as its name makes a bit more sense, and terminates with a message.
|
||||
|
||||
`rssh` solves a specific issue. It's best not to use it unless you need its features, but if you do need them, it's a valuable tool in the kit!
|
||||
|
|
|
|||
|
|
@ -6,13 +6,13 @@ subtitle: Incredibly secure, easy to use, but are it's trade-offs worth it?
|
|||
tags: [security]
|
||||
---
|
||||
|
||||
Throughout my life, I've had many different email providers, starting with [Hotmail](https://hotmail.com) almost 10 years ago. Recently, I've been focusing more on ways I can secure my emails. No, I may not have anything to hide, but [that doesn't matter](http://www.ted.com/talks/glenn_greenwald_why_privacy_matters)!
|
||||
Throughout my life, I've had numerous email providers, starting with [Hotmail](https://hotmail.com) almost 10 years ago. Recently, I've been focusing more on ways I can secure my emails. No, I may not have anything to hide, but [that doesn't matter](http://www.ted.com/talks/glenn_greenwald_why_privacy_matters)!
|
||||
|
||||
Originally I thought the best way to keep things secure, and out of the hands of any government body was to host it all myself. This came with a number of problems, mostly due to my lack of experience running anything like this, which lead to problems with my spam filter blocking legitimate emails, and any emails I did send ending up in their spam folder.
|
||||
|
||||
After searching around for a while, I stumbled on _ProtonMail_, who claimed to be the most secure email host ever. One of their founders did a [TED talk](https://www.ted.com/talks/andy_yen_think_your_email_s_private_think_again), which sold me on the platform.
|
||||
|
||||
ProtonMail use a combination of [open-source technologies](https://github.com/protonmail), a closed-access platform, and swiss data centers to protect emails better than anyone else! The only way you can access your emails is by using their custom apps for Android, iOS, and web. Whilst this is annoying, and means it isn't accessible through protocols such as IMAP and POP3, which would considerably lower the security.
|
||||
ProtonMail uses a combination of [open-source technologies](https://github.com/protonmail), a closed-access platform, and swiss data centers to protect emails better than anyone else! The only way you can access your emails is by using their custom apps for Android, iOS, and web. Whilst this is annoying, and means it isn't accessible through protocols such as IMAP and POP3, which would considerably lower the security.
|
||||
|
||||
Back in April, I signed up to ProtonMail's _Plus_ tier, and switched all my domains to use their servers as an email provider. The set up process itself was incredibly simple, it walks you through every DNS record you needed to create, so all I had to do was copy-paste!
|
||||
|
||||
|
|
|
|||
|
|
@ -1,14 +1,14 @@
|
|||
---
|
||||
title: React-Native intro dev meeting
|
||||
title: React Native intro dev meeting
|
||||
date: 2016-03-16
|
||||
subtitle: Introducing React-Native to the rest of the office
|
||||
subtitle: Introducing React Native to the rest of the office
|
||||
image: https://facebook.github.io/react-native/img/opengraph.png
|
||||
repo: RealOrangeOne/react-native-intro-dev-meeting
|
||||
---
|
||||
|
||||
Recently, at DabApps, we've been migrating our mobile app workflow over to using [react-native](https://facebook.github.io/react-native/) rather than [Ionic](http://ionicframework.com/), mainly because of its near native performance. For the first few projects, there were only a couple of us that knew how to use React Native effectively, and work around the _qwerks_ it has. With the number of app projects growing, we needed to get more people up to speed with the react native workflow, as quickly as possible.
|
||||
Recently, at DabApps, we've been migrating our mobile app workflow over to using [React Native](https://facebook.github.io/react-native/) rather than [Ionic](http://ionicframework.com/), mainly because of its near native performance. For the first few projects, there were only a couple of us that knew how to use React Native effectively, and work around the _qwerks_ it has. With the number of app projects growing, we needed to get more people up to speed with the React Native workflow, as quickly as possible.
|
||||
|
||||
The workflow that we needed to adopt to use react native is an odd one. To keep the quality of our code at the highest possible, whilst keeping the codebase as maintainable as possible. The workflow we use was created by four of us, through experiences with both work and personal projects using the framework, and it works rather well. The only problem was that only four of us actually knew it.
|
||||
The workflow that we needed to adopt to use React Native is an odd one. To keep the quality of our code at the highest possible, whilst keeping the codebase as maintainable as possible. The workflow we use was created by four of us, through experiences with both work and personal projects using the framework, and it works rather well. The only problem was that only four of us actually knew it.
|
||||
|
||||
After a colleague wanted to know more about react-native, and with a couple of potential app projects on the horizon, I created a talk for our (_usually_) bi-weekly dev meetings, with the aim of trying to get everyone up to speed, all in one go.
|
||||
|
||||
|
|
|
|||
|
|
@ -8,7 +8,7 @@ tags: [arch]
|
|||
|
||||
I've been an [Antergos](https://antergos.com/) user for almost three years, and I love it! It's like Arch, but with a simple installation process, and yields a near-pure Arch install, unlike Arch derivatives like [Manjaro](https://manjaro.org/). Unfortunately, on 21st May 2019, the [Antergos project ended](https://antergos.com/blog/antergos-linux-project-ends/). Those behind the project were unable to commit the time the project needed and deserved. I for one want to thank them for the effort they have put in!
|
||||
|
||||
The issue now is what to do with my machines which run Antergos (of which there are currently 5). Technically, I don't need to do anything, the Antergos team state that because existing installs are _basically_ vanilla arch, there's no need to panic and wipe:
|
||||
The issue now is what to do with my machines which run Antergos (of which there are currently 5). Technically, I don't need to do anything, the Antergos team state that because existing installations are _basically_ vanilla arch, there's no need to panic and wipe:
|
||||
|
||||
> For existing Antergos users: there is no need to worry about your installed systems as they will continue to receive updates directly from Arch. Soon, we will release an update that will remove the Antergos repos from your system along with any Antergos-specific packages that no longer serve a purpose due to the project ending.
|
||||
|
||||
|
|
@ -18,7 +18,7 @@ However, some of my machines are due a clean re-install, in a (possibly futile)
|
|||
|
||||
[My dotfiles]({{< relref "dotfiles" >}}) enable quickly setting up machines to exactly how I like, but there's still large amounts of the system installation process it doesn't account for, by design, because it was usually handled by the Antergos installer.
|
||||
|
||||
## 2. Unknown Unknown applications
|
||||
## 2. "Unknown Unknown" applications
|
||||
|
||||
Probably the largest factor which put me off doing something like this earlier, is that Antergos installs a lot of packages the user has no idea about, which result in a more stable system where things actually work. It's hard to work out exactly what these packages are, without doing a deep dive into the installed packages.
|
||||
|
||||
|
|
|
|||
|
|
@ -3,23 +3,23 @@ title: Creating a fast, secure WordPress site
|
|||
date: 2018-10-08
|
||||
---
|
||||
|
||||
In terms of security, [WordPress](https://wordpress.org), and PHP in general for that matter, have become a bit of a [joke](https://eev.ee/blog/2012/04/09/php-a-fractal-of-bad-design/). If you want a site to be secure, people tend to steer clear of WordPress and PHP. That being said, nothing stands even close to WordPress with regards to plugin support, community size, and documentation. As much as we may not like it, I think WordPress isn't going anywhere.
|
||||
In terms of security, [WordPress](https://wordpress.org), and PHP in general for that matter, have become a bit of a [joke](https://eev.ee/blog/2012/04/09/php-a-fractal-of-bad-design/). If you want a site to be secure, people tend to steer clear of WordPress and PHP. That being said, nothing stands even close to WordPress in plugin support, community size, and documentation. As much as we may not like it, I think WordPress isn't going anywhere.
|
||||
|
||||
Recently, I was approached by an old friend to set up a small-scale online store and blog. After doing lots of research into cheap, static options, I eventually settled on WordPress and WooCommerce, on the advice of a colleague. Having never set up a site like this, which relies on being secure, and fairly fast, it was going to be a challenge, and doing it on a shoestring budget was going to make things harder!
|
||||
|
||||
And so, after two weeks of on-and-off poking, research, re-installation and optimisation, and [an oddly timed twitter thread with @CryptoSeb](https://twitter.com/CryptoSeb/status/1035611479800721408), I eventually settled on a setup on how to do it which is secure, fast, and satisfies my inner DevOps' OCD.
|
||||
And so, after two weeks of on-and-off poking, research, re-installation and optimization, and [an oddly timed twitter thread with @CryptoSeb](https://twitter.com/CryptoSeb/status/1035611479800721408), I eventually settled on a set up on how to do it which is secure, fast, and satisfies my inner DevOps' OCD.
|
||||
|
||||
## OS
|
||||
|
||||
Decisions on the OS are fairly simple. For my site, I used Debian. In part because I'd not used it extensively before, and wanted to see if there were any benefits to Ubuntu, my go-to alternative, but also because it's considered to be dependable and secure. The Debian repos are some of the largest, containing any application I could need for a project like this, all of which have been well tested.
|
||||
|
||||
There's nothing about this project, or article, which is Debian specific, or even Linux specific. Running this on something like FreeBSD would work great (and debatably be more secure). Theoretically it's possible to run all these applications on a Windows server. But running a windows server by choice seems crazy to me!
|
||||
There's nothing about this project, or article, which is Debian specific, or even Linux specific. Running this on something like FreeBSD would work great (and debatable be more secure). Theoretically it's possible to run all these applications on a Windows server. But running a Windows server by choice seems crazy to me!
|
||||
|
||||
## Web Server
|
||||
|
||||
Most WordPress tutorials I came across used Apache2 as the web server. The tutorial I used was from [Debian](https://wiki.debian.org/WordPress), so I assumed it contained best-practices. After doing almost all the setup with Apache, page loads were hitting around 10 seconds (wish I'd recorded some actual benchmarks now!), which is far from ideal! After playing around with a couple [cache] plugins, they didn't make much difference, even with a warmed browser cache.
|
||||
|
||||
I tried doing a re-install on a fresh machine, served using NGINX and `php-fpm` instead, dropped page loads down to 1.3 seconds without a cache, and 140ms with! The installation notes I used for that came from the wonderful people at [DigitalOcean](https://www.digitalocean.com/community/tutorials/how-to-install-wordpress-with-lemp-on-debian-9).
|
||||
I tried setting up a fresh machine, served using NGINX and `php-fpm` instead, dropped page loads down to 1.3 seconds without a cache, and 140ms with! The installation notes I used for that came from the wonderful people at [DigitalOcean](https://www.digitalocean.com/community/tutorials/how-to-install-wordpress-with-lemp-on-debian-9).
|
||||
|
||||
The other benefit of NGINX, besides sheer speed, is that it's much simpler. Apache2 has a lot of additional extensions which allow it to do incredible things, most of which we don't need. Because NGINX is much simpler, most of the computation is offloaded to `php-fpm`, which is designed specifically to do these kinds of things. Keeping the processes running the application, and the processes handling things like web routing and SSL separate is almost certainly a good thing.
|
||||
|
||||
|
|
@ -29,7 +29,7 @@ Any site should be using HTTPS now. With services like LetsEncrypt, there's real
|
|||
|
||||
### HTTP2
|
||||
|
||||
[HTTP2](https://http2.github.io/) brings a lot of performance improvements over HTTP 1.1. Enabling it in NGINX is as simple as adding `http2` to the `listen` statement, and WordPress with automatically detect it and optimise. If you require support with very old browsers and OSs, then you may not want to enable this. HTTP2 is very different to HTTP 1.1, both in its structure, and feature-set.
|
||||
[HTTP2](https://http2.github.io/) brings a lot of performance improvements over HTTP 1.1. Enabling it in NGINX is as simple as adding `http2` to the `listen` statement, and WordPress with automatically detect it and optimize. If you require support with very old browsers and OSs, then you may not want to enable this. HTTP2 is very different to HTTP 1.1, both in its structure, and feature-set.
|
||||
|
||||
## Database
|
||||
|
||||
|
|
@ -58,7 +58,7 @@ After you've setup your site, you're going to want to give it a test from the ou
|
|||
|
||||
### `nmap`
|
||||
|
||||
[`nmap`](https://nmap.org/) is a tool to assist with service and device discovery on a network. `nmap` can be pointed at a server, and inform you of services it has open, and what ports they're listening on. This let's you check there's no additional services running on your server that you've not secured. This isn't exactly, but if you want to be super paranoid, and cover all bases, you might as well.
|
||||
[`nmap`](https://nmap.org/) is a tool to assist with service and device discovery on a network. `nmap` can be pointed at a server, and inform you of services it has open, and what ports they're listening on. This lets you check there's no additional services running on your server that you've not secured. This isn't exactly, but if you want to be super paranoid, and cover all bases, you might as well.
|
||||
|
||||
```
|
||||
$ nmap ******
|
||||
|
|
@ -82,4 +82,4 @@ When managing a server running applications such as this, it's important to stay
|
|||
|
||||
The rest of the applications installed on the server can be handled through your OSs package manager (in my case, `apt`).
|
||||
|
||||
WordPress gets a lot of bad reputation with regards to security. But it's more than possible to create something secure, if you make sure to use trusted and battle-tested applications, highly regarded plugins, and don't let your clients install plugins for themselves!
|
||||
WordPress has a bad reputation of security. But it's more than possible to create something secure, if you make sure to use trusted and battle-tested applications, highly regarded plugins, and don't let your clients install plugins for themselves!
|
||||
|
|
|
|||
|
|
@ -6,13 +6,13 @@ image: http://www.nerdoholic.com/wp-content/uploads/2014/07/Cyber-Security-_size
|
|||
tags: [security]
|
||||
---
|
||||
|
||||
As it's [Cyber Security Month](https://cybersecuritymonth.eu/), now's the perfect time to work on improving the security on my websites, projects, and servers. But, upgrading them for now isn't good enough for me, I wanted to add a way of scanning projects automatically, to check for any new issues.
|
||||
As it is [Cyber Security Month](https://cybersecuritymonth.eu/), now is the perfect time to work on improving the security on my websites, projects, and servers. But, upgrading them for now isn't good enough for me, I wanted to add a way of scanning projects automatically, to check for any new issues.
|
||||
|
||||
As most of my projects revolve around Javascript and Python, these are the languages I'll be concentrating on.
|
||||
|
||||
# Javascript
|
||||
## Express Server
|
||||
Express is one the most popular JS servers, and fortunately, they have a [security guide](http://expressjs.com/en/advanced/best-practice-security.html), that contains some of best ways to write secure servers. One of the best and simplest ways is to add the [helmet](https://www.npmjs.com/package/helmet) middleware, a combination of other middleware that drastically increase security. It's incredibly easy to add too, at just [3 lines of code](https://github.com/RealOrangeOne/host-container/commit/90adfd04aed2f2065d803623c297dc1a8ae71632)!
|
||||
Express is one of the most popular JS servers, and fortunately, they have a [security guide](http://expressjs.com/en/advanced/best-practice-security.html), that contains some of the best ways to write secure servers. One of the best and simplest ways is to add the [helmet](https://www.npmjs.com/package/helmet) middleware, a combination of other middleware that drastically increase security. It's incredibly easy to add too, at just [3 lines of code](https://github.com/RealOrangeOne/host-container/commit/90adfd04aed2f2065d803623c297dc1a8ae71632)!
|
||||
|
||||
You can use [securityheaders.io](http://securityheaders.io/) to check if any headers are being sent by your server that shouldn't be, As well as see how you can improve. [Here's](https://securityheaders.io/?q=theorangeone.net&followRedirects=on) the report for my website, powered by my static server [tstatic](https://github.com/RealOrangeOne/tstatic).
|
||||
|
||||
|
|
@ -24,7 +24,7 @@ Keeping dependencies up to date is generally a good thing, and likely to help wi
|
|||
|
||||
# Python
|
||||
## Code
|
||||
Any of the projects I work on that are more advance that a simple static server, are probably Django. Checking the python code itself is nice and simple thanks to [bandit](https://github.com/openstack/bandit). It checks your code to make sure you're writing it properly, catching errors, and using libraries in a secure way.
|
||||
Any of the projects I work on that are more advance that a simple static server, are probably Django. Checking the python code itself is nice and simple thanks to [bandit](https://github.com/openstack/bandit). It checks your code to make sure you're writing it properly, catching errors, and using libraries securely.
|
||||
|
||||
### Dependencies?
|
||||
As with NodeJS, there's a tool that checks dependencies for security issues. But, unlike `nsp`, [safety](https://pypi.python.org/pypi/safety) not only checks your dependencies, but also their dependencies, recursively.
|
||||
|
|
|
|||
|
|
@ -25,7 +25,7 @@ Stage two uses a completely different container as the base, `nginx:latest-alpin
|
|||
|
||||
This container is built using GitHub actions, automatically on push, and then uploaded to GitHubs package registry. A [docker-compose configuration](https://github.com/RealOrangeOne/infrastructure/blob/master/ansible/roles/docker/files/theorangeone.net/docker-compose.yml) is pre-installed on my server, pointed at this container, and with the necessary Traefik rules to route traffic correctly.
|
||||
|
||||
To maintain auto-deployment functionality, something I find really important, I run [watchtower](https://containrrr.github.io/watchtower/). Watchtower polls the upstream of all containers I depend on, and when there's changes, automatically pulls and restarts them. The poll interval is five minutes, so it's a slower update than Netlify, but for my needs it's fine. Generally this is ill-advised as it can cause containers to update unexpectedly, but I pin containers properly, so i'm not worried.
|
||||
To maintain auto-deployment functionality, something I find really important, I run [watchtower](https://containrrr.github.io/watchtower/). Watchtower polls the repositories of all the containers I depend on, and when there are changes, automatically pulls and restarts them. The poll interval is five minutes, so it's a slower update than Netlify, but for my needs it's fine. Generally this is ill-advised as it can cause containers to update unexpectedly, but I pin containers properly, so I'm not worried.
|
||||
|
||||
## Success?
|
||||
|
||||
|
|
|
|||
|
|
@ -4,7 +4,7 @@ date: 2019-04-28
|
|||
subtitle: Just don't be a dick - It's not that difficult!
|
||||
---
|
||||
|
||||
Spoiling movies is something which has plagued people since forever. If something dramatic happens, of course people don't want to find out by just being told, they want to watch and experience it for themselves. Unfortunately, it seems many people take pride and pleasure in spoiling films for people.
|
||||
Spoiling films is something which has plagued people since forever. If something dramatic happens, of course people don't want to find out by just being told, they want to watch and experience it for themselves. Unfortunately, it seems many people take pride and pleasure in spoiling films for people.
|
||||
|
||||
In the last two weeks, we've had both Season eight of Game of Thrones, and Avengers endgame released. Both of which are long-awaited finales to large franchises, and all contain story points which should not be spoiled. I've never quite been able to understand how it's so difficult to not talk about spoilers, whether this be on the internet, in a professional environment, or even down the pub. No matter where you are, you're going to bump into people who won't have seen it yet, and don't appreciate having to hear you talk about it.
|
||||
|
||||
|
|
@ -15,7 +15,7 @@ There's two really simply rules when it comes to spoilers:
|
|||
1. If you've seen a film with a plot point which could be considered a plot spoiler, be careful where you talk about it. Be careful of anyone in earshot, and don't have conversations in public channels.
|
||||
2. If you simply _have_ to talk about something, check that those around either don't care, have already seen it, or are far enough away they can't hear you
|
||||
|
||||
Both of which can be summarised by "Don't be a dick" and "Use common sense".
|
||||
Both of which can be summarized by "Don't be a dick" and "Use common sense".
|
||||
|
||||
## Just be considerate
|
||||
|
||||
|
|
@ -23,14 +23,14 @@ Whether someone intends to see a film or not, be considerate they may not want t
|
|||
|
||||
If you're in an environment like an office, where there's going to be many people with different opinions, just don't talk about it!
|
||||
|
||||
One of the worst examples I've seen of someone not quite understanding spoilers, is self-imposing a 48 hour buffer where you can't talk about it. On the face of it, this seems reasonable, until you realise that after said 48 hours, anyone can talk about it with 0 consequences, which is definitely less than reasonable. Rest assured said person was quickly put in their place!
|
||||
One of the worst examples I've seen of someone not quite understanding spoilers, is self-imposing a 48-hour buffer where you can't talk about it. On the face of it, this seems reasonable, until you realize that after said 48 hours, anyone can talk about it with 0 consequences, which is definitely less than reasonable. Rest assured said person was quickly put in their place!
|
||||
|
||||
## _"When is it ok to talk about possible spoilers?"_
|
||||
## _"When is it OK to talk about possible spoilers?"_
|
||||
|
||||
That's a difficult question. Simply not talking about any film forever is quite crazy, and will kill any hype around a film and many communities. There definitely has to be some point at which films are ok to talk about, because we're already doing it. I think it's quite safe to assume everyone knows Darth Vader is Luke's father (if you didn't, I'm sorry, but also you're missing out!).
|
||||
That's a difficult question. Simply not talking about any film forever is quite crazy, and will kill any hype around a film and many communities. There definitely has to be some point at which films are OK to talk about, because we're already doing it. I think it's quite safe to assume everyone knows Darth Vader is Luke's father (if you didn't, I'm sorry, but also you're missing out!).
|
||||
|
||||
I suspect there's no _"Golden rule"_ for this, just apply some common sense. If a film isn't out on DVD yet, or on Netflix, it's safe to say many people haven't seen it yet. I suspect it'll be some kind of buffer around the point on DVD, although even that doesn't quite work. For example "Star Wars: The Last Jedi" was in cinemas in December 2017, but I would still think twice before talking about _certain_ plot points out loud.
|
||||
|
||||
## TL;DR
|
||||
|
||||
As the subtitle says: Just don't be a dick - It's not that difficult!
|
||||
As the subtitle says: Just don't be a dick. It's not that difficult!
|
||||
|
|
|
|||
|
|
@ -11,7 +11,7 @@ This year marks the 3rd year of my pattern for publishing a "My Stack" post, not
|
|||
|
||||
## OS
|
||||
|
||||
For the last couple years, I've been an avid [Antergos](https://web.archive.org/web/20190903082315/https://antergos.com/) user, but May of this year saw [the project end](https://web.archive.org/web/20190809064653/https://antergos.com/blog/antergos-linux-project-ends), forcing me to move. With all my [dotfiles]({{< relref "dotfiles" >}}) configured for an arch-based base, I had little choice than moving to Arch. [Manjaro](https://manjaro.org/) also looked promising, but I'd wanted to move to Vanilla [Arch](https://www.archlinux.org/) for a while, so this felt like as good of a time as any.
|
||||
For the last couple years, I've been an avid [Antergos](https://web.archive.org/web/20190903082315/https://antergos.com/) user, but May of this year saw [the project end](https://web.archive.org/web/20190809064653/https://antergos.com/blog/antergos-linux-project-ends), forcing me to move. With all my [dotfiles]({{< relref "dotfiles" >}}) configured for an arch-based base, I had little choice other than moving to Arch. [Manjaro](https://manjaro.org/) also looked promising, but I'd wanted to move to Vanilla [Arch](https://www.archlinux.org/) for a while, so this felt like as good of a time as any.
|
||||
|
||||
7 months later, I've only hard migrated three machines, the rest still run Antergos, and they still run fine. The Antergos repos don't exist any more, but Antergos was really just an installer for vanilla arch with an extra repo, so the fact everything still _just works_ doesn't surprise me.
|
||||
|
||||
|
|
@ -24,13 +24,13 @@ I'm still an i3 user. I recently [tried using macOS]({{< relref "macos-review" >
|
|||
|
||||
My editor situation also hasn't changed much in the last year. I still use [VSCode](https://code.visualstudio.com/), although the config has been slightly thinned out so remove extensions I don't use. I recently tried switching back to [IntelliJ](https://www.jetbrains.com/idea/), for the far superior intellisense, but it just didn't feel right, and felt incredibly heavy, not to mention the lack of automatable configuration.
|
||||
|
||||
Last year I used [GhostWriter](https://github.com/wereturtle/ghostwriter/) for my markdown editing, but recently I transitioned that into VSCode so I don't need to remember two sets of keyboard shortcuts. The fancy WYSIWIG formatting from GhostWriter wasn't a benefit to me, but it's still my recommended markdown editor.
|
||||
Last year I used [GhostWriter](https://github.com/wereturtle/ghostwriter/) for my markdown editing, but recently I transitioned that into VSCode, so I don't need to remember two sets of keyboard shortcuts. The fancy WYSIWIG formatting from GhostWriter wasn't a benefit to me, but it's still my recommended markdown editor.
|
||||
|
||||
[Vim](https://www.vim.org/) is still my terminal editor of choice, but I am looking for something simpler. Some friends often preach [Nano](https://www.nano-editor.org/), which can apparently do many of the editing features Vim has, but the muscle memory is quite hard to get rid of. My [dotfiles]({{< relref "dotfiles" >}}) currently sync a custom Vim configuration, which much like my VSCode configuration, I've also thinned out, but I think there's more thinning to do.
|
||||
|
||||
## Shell
|
||||
|
||||
Naturally, I do spent much of my time in the shell. I still use [ZSH](https://www.zsh.org/), [Alacritty](https://github.com/jwilm/alacritty/) and [Tmux](https://github.com/tmux/tmux), and it fulfils everything I want to do. my only gripe is that clipboard management is pretty weird, somewhere.
|
||||
Naturally, I do spend much of my time in the shell. I still use [ZSH](https://www.zsh.org/), [Alacritty](https://github.com/jwilm/alacritty/) and [Tmux](https://github.com/tmux/tmux), and it fulfils everything I want to do. my only gripe is that clipboard management is pretty weird, somewhere.
|
||||
|
||||
Copying multi-line text from the terminal into the system clipboard just doesn't work, and I've not been able to work out why. My current solution is [`tmux-yank`](https://github.com/tmux-plugins/tmux-yank), but that changes the mechanism to copy to the clipboard, which takes a lot to remember. Some day I'll work out what the issue is and fix things, I hope. But for now, this is fine.
|
||||
|
||||
|
|
@ -60,25 +60,25 @@ Password management is something I feel quite strongly about. Really, everyone s
|
|||
|
||||
<div style="max-width:854px; margin: 0 auto"><div style="position:relative;height:0;padding-bottom:56.25%"><iframe src="https://embed.ted.com/talks/glenn_greenwald_why_privacy_matters" width="854" height="480" style="position:absolute;left:0;top:0;width:100%;height:100%" frameborder="0" scrolling="no" allowfullscreen></iframe></div></div>
|
||||
|
||||
Currently, I use [Enpass](https://www.enpass.io/). Enpass has a crazy amount of features, and can by synced between devices using my Nextcloud server. Enpass isn't open-source, which annoys me, but really it's the best there is. The only real feature keeping me is the versatility of entries. Entries are really just a list of fields. Each field can have various different types, be private, or contain files, email addresses or TOTP tokens. [KDBX](https://keepass.info/help/kb/kdbx_4.html), the format behind [KeePass](https://keepass.info/) doesn't support this in quite the same way. You can add random other entries, but it's not the same. The day this is added to KeePass, I'm switching, immediately.
|
||||
Currently, I use [Enpass](https://www.enpass.io/). Enpass has a crazy amount of features, and can be synced between devices using my Nextcloud server. Enpass isn't open-source, which annoys me, but really it's the best there is. The only real feature keeping me is the versatility of entries. Entries are really just a list of fields. Each field can have various different types, be private, or contain files, email addresses or TOTP tokens. [KDBX](https://keepass.info/help/kb/kdbx_4.html), the format behind [KeePass](https://keepass.info/) doesn't support this in quite the same way. You can add random other entries, but it's not the same. The day this is added to KeePass, I'm switching, immediately.
|
||||
|
||||
## VPN
|
||||
|
||||
If you frequent public WiFi, you need a VPN. I don't think VPNs are necessary for everyday use (even though my phone is always connected to one), but if you're on a public or untrusted network, you definitely need one.
|
||||
If you frequent public Wi-Fi, you need a VPN. I don't think VPNs are necessary for everyday use (even though my phone is always connected to one), but if you're on a public or untrusted network, you definitely need one.
|
||||
|
||||
Probably the most famous is [NordVPN](https://nordvpn.com/), simply because of the amount of advertising they do. I don't trust them very much.
|
||||
|
||||
My current VPN of choice is [Private Internet Access](https://www.privateinternetaccess.com/) (PIA). They have pretty good clients, a large number of servers, and a SOCKS5 proxy, which is often handy. PIA was recently bought out, and [reddit](https://www.reddit.com/r/Piracy/comments/dyqdno/private_internet_access_bought_out_by_cyber_ghost/) wasn't to happy about this. Since that they've open-sourced their desktop client, and have committed to improving transparency. I'm personally a large fan of [Mullvad](https://mullvad.net/en/), and they're definitely a close second, but for now, I think I'm sticking with PIA.
|
||||
My current VPN of choice is [Private Internet Access](https://www.privateinternetaccess.com/) (PIA). They have pretty good clients, lots of servers, and a SOCKS5 proxy, which is often handy. PIA was recently bought out, and [reddit](https://www.reddit.com/r/Piracy/comments/dyqdno/private_internet_access_bought_out_by_cyber_ghost/) wasn't too happy about this. Since that they've open-sourced their desktop client, and have committed to improving transparency. I'm personally a large fan of [Mullvad](https://mullvad.net/en/), and they're definitely a close second, but for now, I think I'm sticking with PIA.
|
||||
|
||||
## Email
|
||||
|
||||
I've been a pretty loyal [Fastmail](https://ref.fm/u19842056) user for a couple years now. It's not encrypted at rest like [ProtonMail](https://protonmail.com/), but they claim very high levels of privacy, and the feature list is incredible!
|
||||
I've been a pretty loyal [Fastmail](https://ref.fm/u19842056) user for a couple of years now. It's not encrypted at rest like [ProtonMail](https://protonmail.com/), but they claim very high levels of privacy, and the feature list is incredible!
|
||||
|
||||
As a client, I still quite like [Thunderbird](https://www.thunderbird.net/). I tried [Mailspring](https://getmailspring.com/), [Evolution](https://wiki.gnome.org/Apps/Evolution/), and just the web UI, but Thunderbird is really nice in terms of features and performance, and the calendar integration is really handy. Since Mozilla stopped supporting it, the community has picked it back up, and there's now full-time work being done on it, and it's improving quite a lot. But there's still quite a long way to go before it's really ready to start recommending to people.
|
||||
|
||||
## RSS
|
||||
|
||||
For the last two or so years now, I've been a heavy RSS user. I've fully replaced YouTube subscriptions with it, because the subscription management is famously garbage.
|
||||
For the last two or so years now, I've been a heavy RSS user. I've fully replaced YouTube subscriptions with it, because the subscription management is famously rubbish.
|
||||
|
||||
As an aggregator, I use [tt-rss](https://tt-rss.org/). [Last year]({{< relref "my-stack-2018" >}}) I said the UI was hard to get to grips with, but after spending more and more time with [FreshRSS](https://www.freshrss.org/), their UI got on my nerves even more.
|
||||
|
||||
|
|
@ -102,6 +102,6 @@ I'm still a [Pocketcasts](https://www.pocketcasts.com/) user, but recent updates
|
|||
|
||||
## Notes
|
||||
|
||||
This is a category i'm in desperate need of improving. I currently use [Turtl](https://turtlapp.com/), which is a nice, self-hosted, encrypted notes app, but it's not very active, and the interface is a bit clunky, but as features go, it's perfect!
|
||||
This is a category I'm in desperate need of improving. I currently use [Turtl](https://turtlapp.com/), which is a nice, self-hosted, encrypted notes app, but it's not very active, and the interface is a bit clunky, but as features go, it's perfect!
|
||||
|
||||
Most of the note apps seem to be designed for larger notes, rather than tiny bits of text / lists, but it seems that's a niche. I think Turtl may be here to stay, but i'm still on the lookout.
|
||||
Most of the note apps seem to be designed for larger notes, rather than tiny bits of text / lists, but it seems that's a niche. I think Turtl may be here to stay, but I'm still on the lookout.
|
||||
|
|
|
|||
|
|
@ -4,7 +4,7 @@ date: 2020-05-01
|
|||
image: https://docs.traefik.io/assets/img/traefik-architecture.png
|
||||
---
|
||||
|
||||
[Traefik](https://docs.traefik.io/) is a cloud native reverse proxy. Which is basically a fancy way of saying it's a reverse proxy with some fancy features. Namely fancy features around auto-discovery, and deep integration with technologies like Docker and Kubernetes.
|
||||
[Traefik](https://docs.traefik.io/) is a cloud native reverse proxy, which is basically a fancy way of saying it's a reverse proxy with some fancy features. Specifically it has fancy features around auto-discovery, and deep integration with technologies like Docker and Kubernetes.
|
||||
|
||||
## Basic concepts
|
||||
|
||||
|
|
@ -40,11 +40,11 @@ One thing to note about this is the `network_mode: host`. Traefik needs to be ab
|
|||
|
||||
## Traefik configuration
|
||||
|
||||
Traefik configuration is split in 2. Traefik's primary configuration can be either YAML or TOML. Configuration for the services themselves can live in many different places. For docker-compose, it's done using container labels.
|
||||
Traefik configuration is split in 2. Traefik's primary configuration can be either YAML or TOML. Configuration for the services themselves can live in many places. For docker-compose, it's done using container labels.
|
||||
|
||||
Traefiks main configuration allows you to configure the entrypoints for traefik to listen on, how TLS is configured, and where traefik should look for services.
|
||||
|
||||
The docker configuration for traefik is probably what turns most people off of it. Traefik's configuration may seem verbose to achieve something which would be very straightforward with Nginx or alike. But if you approach things in a different way, they can be very clean.
|
||||
The docker configuration for traefik is probably what turns most people off of it. Traefik's configuration may seem verbose to achieve something which would be very straightforward with Nginx or alike. But if you approach things differently, they can be very clean.
|
||||
|
||||
My typical configuration is very simple:
|
||||
|
||||
|
|
@ -130,7 +130,7 @@ http:
|
|||
- hsts
|
||||
```
|
||||
|
||||
The services is set to `ping@internal` just because routers need a service. The ping service is built-in to Traefik, and just returns `200 OK` to all requests, not that it'll be hit, as the `redirectScheme` middleware will redirect traffic before it hits the service.
|
||||
The service is set to `ping@internal` because routers need a service. The ping service is built-in to Traefik, and just returns `200 OK` to all requests, not that it'll be hit, as the `redirectScheme` middleware will redirect traffic before it hits the service.
|
||||
|
||||
Now, we just add our newly created file provider:
|
||||
|
||||
|
|
@ -155,7 +155,7 @@ First, you'll need to setup and install traefik, which can be done with a very s
|
|||
|
||||
Once you already have traefik installed and setup, adding services is very simple:
|
||||
|
||||
Step 1, pick an application, find a container, and write a minimal compose file:
|
||||
Step 1: pick an application, find a container, and write a minimal compose file:
|
||||
|
||||
```yml
|
||||
version: "2.3"
|
||||
|
|
@ -167,7 +167,7 @@ services:
|
|||
restart: unless-stopped
|
||||
```
|
||||
|
||||
Step 2, add the absolute minimum traefik configuration:
|
||||
Step 2: add the absolute minimum traefik configuration:
|
||||
|
||||
```yml
|
||||
version: "2.3"
|
||||
|
|
@ -182,9 +182,9 @@ services:
|
|||
- "traefik.http.routers.whoami.rule=Host(`whoami.example.com`)"
|
||||
```
|
||||
|
||||
Step 3, start your new service with `docker-compose up -d`, and wait a few seconds for traefik to notice it. You can check on the progress of this by refreshing the dashboard until it appears.
|
||||
Step 3: start your new service with `docker-compose up -d`, and wait a few seconds for traefik to notice it. You can check on the progress of this by refreshing the dashboard until it appears.
|
||||
|
||||
Step 4, visit the URL in your browser, and notice traffic being routed correctly.
|
||||
Step 4: visit the URL in your browser, and notice traffic being routed correctly.
|
||||
|
||||
To add more applications, just start more compose files with more configuration. Traefik will pick up on new containers automatically and start routing traffic, no restart required.
|
||||
|
||||
|
|
@ -192,6 +192,6 @@ To add more applications, just start more compose files with more configuration.
|
|||
|
||||
This is a more difficult question than it may seem. Personally I'm super happy I migrated from Nginx to traefik, and I know plenty of others who feel the same. If you're trying to manage a number of different docker containers on one machine, then traefik is something worth looking into.
|
||||
|
||||
However, if you've just got a couple services, and you're comfortable with Nginx, why rock the boat? Both traefik and nginx are reverse proxies, and they're both really good, you're not going to see performance, security, or really simplicity gains by switching. With that said if you're using docker, it's worth a look into anyway.
|
||||
However, if you've just got a couple services, and you're comfortable with Nginx, why rock the boat? Both traefik and nginx are reverse proxies, and they're both great. You're not going to see performance, security, or really simplicity gains simply from switching. With that said if you're using docker, it's worth a look into anyway.
|
||||
|
||||
Using Traefik using only the file provider is definitely not a good idea, and nginx is definitely a better tool for the job!
|
||||
|
|
|
|||
|
|
@ -4,7 +4,7 @@ date: 2018-06-21
|
|||
image: resource:user-settings.png
|
||||
---
|
||||
|
||||
VPNs are a way of accessing application which sit on a separate network using an encrypted tunnel. Contrary to popular belief, they are not designed to be used for anonymising your internet habits. Whilst VPNs are designed to enable a client to access the servers network, it's possible to use them to provide a server to access to its client's network. With this, and a simple HTTP server, it's possible to open up applications on your home network to the internet, without the need for a static IP, or a port forward!
|
||||
VPNs are a way of accessing application which sit on a separate network using an encrypted tunnel. Contrary to popular belief, they are not designed to anonymize your internet habits. Whilst VPNs are designed to enable a client to access the servers network, it's possible to use them to provide a server to access to its client's network. With this, and a simple HTTP server, it's possible to open up applications on your home network to the internet, without the need for a static IP, or a port forward!
|
||||
|
||||
{{<mermaid caption="Network layout">}}
|
||||
graph LR
|
||||
|
|
@ -74,7 +74,7 @@ Do you wish to login to the Admin UI as "openvpn"?
|
|||
> Press ENTER for default [yes]: yes
|
||||
```
|
||||
|
||||
OpenVPN Access Server is free for two concurrent users. For this, we only need, so no need to enter a license key.
|
||||
OpenVPN Access Server is free for two concurrent users. For this, we only need, so no need to enter a licence key.
|
||||
|
||||
Once the script has finished, you'll need to set the password for the builtin user. Run `sudo passwd openvpn` to do this. Open the _"Admin UI"_ URL displayed after the init script. It's probably `https://<ip>:943/admin`. Here, you can log in as the `openvpn` user.
|
||||
|
||||
|
|
@ -159,4 +159,4 @@ server {
|
|||
}
|
||||
```
|
||||
|
||||
And that's it! No port forwarding, no device enumeration, no service enumeration, no hacks. Any device on your network can be made accessible to the world, but only when you want them to. And because it's forwarding using a VPN, it doesn't have to be simply web traffic!
|
||||
And that's it! No port forwarding, no device enumeration, no service enumeration, no hacks. Any device on your network can be made accessible to the world, but only when you want them to. And because it's forwarding using a VPN, it doesn't have to be simply HTTP traffic!
|
||||
|
|
|
|||
|
|
@ -4,15 +4,15 @@ date: 2017-11-13
|
|||
image: resource:new-site-screenshot.png
|
||||
---
|
||||
|
||||
I've had a website for around four years now, starting with a python CGI-based site hosted at [1&1](https://www.1and1.co.uk/), and evolving into it's current form, powered by [Hugo](https://gohugo.io/).
|
||||
I've had a website for around four years now, starting with a python CGI-based site hosted at [1&1](https://www.1and1.co.uk/), and evolving into its current form, powered by [Hugo](https://gohugo.io/).
|
||||
|
||||
Although I'm a web developer, I'm very far from a designer. I really can't design anything!
|
||||
|
||||
## Alternatives
|
||||
In the past, I've used services like [StartBootstrap](https://startbootstrap.com/) and [HTML5UP](https://html5up.net/). These allow me to just throw together a site, and not really worry how it looks, because the design is done for me. The issue with these is that any slight modifications I need to make to the theme, end up spiralling out of control and wrecking the theme.
|
||||
In the past, I've used services like [StartBootstrap](https://startbootstrap.com/) and [HTML5UP](https://html5up.net/). These allow me to just throw together a site, and not really worry how it looks, because the design is done for me. However, slight modifications I need to make to the theme, end up spiralling out of control and wrecking things.
|
||||
|
||||
## Solution
|
||||
After deciding to do yet another redesign, I had an epiphany. Rather than using a fancy, modern-looking design, let's use something simple! The Hugo theme [_Vec_](https://themes.gohugo.io/hugo-theme-vec/) looked _almost_ perfect. I used _Vec_ as a base for a complete redesign of my site. Rather than actually using _Vec_, I used Bootstrap to replicate it closely, with a few optimisations of my own.
|
||||
After deciding to do yet another redesign, I had an epiphany. Rather than using a fancy, modern-looking design, let's use something simple! The Hugo theme [_Vec_](https://themes.gohugo.io/hugo-theme-vec/) looked _almost_ perfect. I used _Vec_ as a base for a complete redesign of my site. Rather than actually using _Vec_, I used Bootstrap to replicate it closely, with a few optimizations of my own.
|
||||
|
||||
Making the design this simple means there's very little to go wrong. If the whole site looks so simple, it's very hard for it to look quite so bad.
|
||||
|
||||
|
|
|
|||
|
|
@ -22,23 +22,23 @@ Having a simple command-line interface is also really handy to quickly iterate o
|
|||
|
||||
## No customization
|
||||
|
||||
Whilst i've said it's got a lot of features, most of them are an inherent part of the system. Wireguard in itself actually doesn't let you custommize much, which sounds like a drawback, but it's really not. There's no complex configuration around authentication, authorization, or any auth backends, nor is there configuration for different encryption standards. You use what's provided, or you use something else.
|
||||
Whilst I've said it's got a lot of features, most of them are an inherent part of the system. Wireguard in itself actually doesn't let you customize much, which sounds like a drawback, but it's really not. There's no complex configuration around authentication, authorization, or any auth backends, nor is there configuration for different encryption standards. You use what's provided, or you use something else.
|
||||
|
||||
In this way, Wireguard is very unix-y. If you need to do something Wireguard doesn't, there's a different tool you can use, which will probably do a better job than Wireguard ever could, or should. Most of the time, the tool you want is `iptables`, something I wouldn't wish on my worst enemy.
|
||||
|
||||
## Built in, almost
|
||||
|
||||
Not that installing Wireguard is especially difficult, but soon it'll be built in, to Linux anyway. As of kernel 5.6, it's right there, ready to use, no installation required. In theory it'll also be backported into Ubuntu 20.04 ready for it's release, so people using LTS versions can be reliably using it for years to come.
|
||||
Not that installing Wireguard is especially difficult, but soon it'll be built in, to Linux anyway. As of kernel 5.6, it's right there, ready to use, no installation required. In theory, it'll also be backported into Ubuntu 20.04 ready for its release, so people using LTS versions can be reliably using it for years to come.
|
||||
|
||||
Linus Torvalds, the creator of Linux, has a great quote about Wireguard: "Can I just once again state my love for it and hope it gets merged soon? Maybe the code isn’t perfect, but I’ve skimmed it, and compared to the horrors that are OpenVPN and IPSec, it’s a work of art."
|
||||
|
||||
## Not _chatty_
|
||||
|
||||
Wireguard is a very clean protocol, it'll only send packets when there's something to talk about. There's no handshake needed to setup a tunnel. There's a small handshake needed to keep the tunnel alive if you're behind NAT, but that's about it. If there's no data to send, there's no data transmitted. On top of this, Wireguard will only respond to authenticated and authorized packets - Any other garbage is just dropped. This maekes it impossible to scan the internet and discover Wireguard servers, which is nice.
|
||||
Wireguard is a very clean protocol, it'll only send packets when there's something to talk about. There's no handshake needed to set up a tunnel. There's a small handshake needed to keep the tunnel alive if you're behind NAT, but that's about it. If there's no data to send, there's no data transmitted. On top of this, Wireguard will only respond to authenticated and authorized packets, any other rubbish is just dropped. This makes it impossible to scan the internet and discover Wireguard servers, which is nice.
|
||||
|
||||
## Small
|
||||
|
||||
The Wireguard codebase is nice and small. Compared to OpenVPN it's practically microscopic. There's an obvious reason for this, it does a lot lesss. A smaller codebase makes it significantly easier to audit, and less code means there's _theoretically_ less to go wrong.
|
||||
The Wireguard codebase is nice and small. Compared to OpenVPN it's practically microscopic. There's an obvious reason for this, it does a lot less. A smaller codebase makes it significantly easier to audit, and less code means there's _theoretically_ less to go wrong.
|
||||
|
||||
## Performance
|
||||
|
||||
|
|
@ -48,7 +48,7 @@ Wireguard is incredibly fast. Take these benchmarks from the Wireguard website,
|
|||
Wireguard benchmarks. [src](https://www.Wireguard.com/performance/#results)
|
||||
{{< /resource >}}
|
||||
|
||||
Not only is Wireguard significantly faster than OpenVPN, and sligtly faster still than IPSec, there's an important extra bit of detail. The Wireguard version was the only one not maxing out the CPU, meaning whatever's limitting Wireguard's score, it's not Wireguard itself, it's likely something far more fundemental like networking overhead, seeing as 1011mb is pretty close to one gigabit.
|
||||
Not only is Wireguard significantly faster than OpenVPN, and slightly faster still than IPSec, there's an important extra bit of detail. The Wireguard version was the only one not maxing out the CPU, meaning whatever's limiting Wireguard's score, it's not Wireguard itself, it's likely something far more fundamental like networking overhead, seeing as 1011mb is pretty close to one gigabit.
|
||||
|
||||
What's yet more scary impressive is this [quote](https://www.Wireguard.com/performance/#performance-roadmap):
|
||||
|
||||
|
|
@ -56,4 +56,4 @@ What's yet more scary impressive is this [quote](https://www.Wireguard.com/perfo
|
|||
|
||||
## More
|
||||
|
||||
If you're thinking to yoursef "This sounds great, where can I get started?", then you're in luck! Not only is the [Wireguard website](https://www.Wireguard.com/) a pretty good resource, but i've got a pretty good [getting started guide]({{< relref "posts/wireguard-getting-started" >}}), if I do say so myself
|
||||
If you're thinking to yourself "This sounds great, where can I get started?", then you're in luck! Not only is the [Wireguard website](https://www.Wireguard.com/) a pretty good resource, but I've got a pretty good [getting started guide]({{< relref "posts/wireguard-getting-started" >}}), if I do say so myself.
|
||||
|
|
|
|||
|
|
@ -7,7 +7,7 @@ Wireguard is taking the VPN world by storm, coming very close to the current cha
|
|||
|
||||
## What is wireguard?
|
||||
|
||||
> WireGuard® is an extremely simple yet fast and modern VPN that utilizes state-of-the-art cryptography. It aims to be faster, simpler, leaner, and more useful than IPsec, while avoiding the massive headache. It intends to be considerably more performant than OpenVPN. WireGuard is designed as a general purpose VPN for running on embedded interfaces and super computers alike, fit for many different circumstances. Initially released for the Linux kernel, it is now cross-platform (Windows, macOS, BSD, iOS, Android) and widely deployable. It is currently under heavy development, but already it might be regarded as the most secure, easiest to use, and simplest VPN solution in the industry.
|
||||
> WireGuard® is an extremely simple yet fast and modern VPN that utilizes state-of-the-art cryptography. It aims to be faster, simpler, leaner, and more useful than IPsec, while avoiding the massive headache. It intends to be considerably more performant than OpenVPN. WireGuard is designed as a general purpose VPN for running on embedded interfaces and super computers alike, fit for many circumstances. Initially released for the Linux kernel, it is now cross-platform (Windows, macOS, BSD, iOS, Android) and widely deployable. It is currently under heavy development, but already it might be regarded as the most secure, easiest to use, and simplest VPN solution in the industry.
|
||||
|
||||
https://www.wireguard.com/
|
||||
|
||||
|
|
@ -16,7 +16,7 @@ Wireguard is not only lighter weight than OpenVPN, it's simpler, smaller, and mo
|
|||
|
||||
## Getting started with Wireguard
|
||||
|
||||
There is an [official quick start guide](https://www.wireguard.com/quickstart/), however as someone just getting started with wireguard, and has little experience in the Linux network stack, it was a lot to try and understand at once. There is however a much simpler way of getting started: `wg-quick`.
|
||||
There is an [official quick start guide](https://www.wireguard.com/quickstart/), however as someone just getting started with wireguard, and with little experience in the Linux network stack, it was a lot to understand at once. There is however a much simpler way of getting started: `wg-quick`.
|
||||
|
||||
`wg-quick` creates standard wireguard tunnels, but generates the underlying commands for you, even printing them as it goes, so you can see how it's working.
|
||||
|
||||
|
|
@ -44,7 +44,7 @@ This creates two files, `publickey` and `privatekey` which contain, well, the pu
|
|||
|
||||
Wireguard's configuration lives in `ini` files in `/etc/wireguard/*.conf`, where `*` is the name of the wireguard interface (that'll be useful later).
|
||||
|
||||
Be sure to take care when specifying keys. Be sure to specify the correct keys for the correct device, else you'll receive configuration error
|
||||
Be sure to take care when specifying keys. Be sure to specify the correct keys for the correct device, else you'll receive configuration error.
|
||||
|
||||
#### Server configuration
|
||||
|
||||
|
|
|
|||
|
|
@ -49,7 +49,7 @@ HAProxy is generally used as a load balancer, but it works perfectly fine with a
|
|||
|
||||
When building a tunnel like this, it's important for each end of the tunnel to reconnect in the event of issues. This was an incredibly annoying caveat with OpenVPN, but wireguard deals with this very well.
|
||||
|
||||
To do this, we simply enable a systemd service, based on the name of the config file. If the config if `/etc/wireguard/my-tun.conf`, then enable `wg-quick@my-tun.service`.
|
||||
To do this, we simply enable a systemd service, based on the name of the config file. If the config is at `/etc/wireguard/my-tun.conf`, then enable `wg-quick@my-tun.service`.
|
||||
|
||||
## Forward traffic down the tunnel
|
||||
|
||||
|
|
@ -64,7 +64,7 @@ listen https
|
|||
server default 10.1.10.2:443 send-proxy
|
||||
```
|
||||
|
||||
Once this is added, restart HAProxy, and you're done. Open the remote IP on on the port you set it to listen on, and watch as you see a request from the client be responded to. And because this is in TCP mode, this traffic can be anything (TCP based, obviously). Need something secure, setup an SSL cert with NGINX, and that'll work with no further configuration
|
||||
Once this is added, restart HAProxy, and you're done. Open the remote IP on the port you set it to listen on, and watch as you see a request from the client be responded to. And because this is in TCP mode, this traffic can be anything (TCP based, obviously). Need something secure, set up an SSL cert with NGINX, and that'll work with no further configuration.
|
||||
|
||||
## Maintaining IPs
|
||||
|
||||
|
|
|
|||
Loading…
Reference in a new issue